 域名頻道IDC知識庫
域名頻道IDC知識庫我們在開發網站程序的時候都會用到數據庫,而數據庫的性能對網站的運行速度是至關重要的。而要想實現高性能數據庫服務器,集群是最好的選擇。
高性能數據庫集群方案:讀寫分離。 其目的在于將訪問壓力分散到集群中的多個節點,減輕高并發現的訪問壓力,但是沒有分散存儲壓力。
讀寫分離的基本架構圖如下:
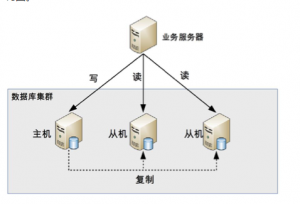
一主對從或者一主一從,主節點負責讀寫操作,從節點負責讀操作。
主從分離的實現:
1、數據庫搭建主從集群,一主多從或者一主一從
2、主機負責讀寫操作,從機負責讀操作
3、主機通過復制將數據同步到從機,從而使每一個數據庫都保證數據的一致性
主從同步的具體原理:
將主機的數據復制到多個從機(slaves)中,同步過程中,主機將數據庫的操作寫到二進制日志(binary log)中,從機打開一個io線程,打開和主機的連接,并將主機的更新日志寫入從機的中繼日志中,從機開一個sql線程讀取中繼日志中的數據,進行更新,從而保證數據的主從數據的一致。
我們在這里為了數據庫的高性能引入了主從分離,但是往往在做架構時,會因為提高系統的高性能,高可用等,引入一些操作,會增加系統的復雜度。 主從的實現不是難點,難點在于引入主從后復雜度隨之而來的解決方案。
讀寫分離,增加了主從復制延遲 和分配機制兩個負責度。
1、主從復制延遲
以 MySQL 為例,主從復制延遲可能達到 1 秒,如果有大量數據同步,延遲 1 分鐘也是有可能的。主從復制延遲會帶來一個問題:業務服務器將數據寫入數據庫主服務器立刻進行讀取,但此時讀操作的的訪問時從機,主機還沒有將數據復制到從機,所以此時查詢會有問題。(比如用戶剛進行注冊,但是登錄的時候卻說無此用戶)
有以下幾種解決方案:
1、根據業務來區分,關鍵業務的讀寫全部指向主機,非關鍵業務采用讀寫分離
2、加入redis,將redis中數據的過期時間設置為主從延遲的時間,當進行訪問時,redis中有數據,則說明主從同步未完成,若redis中無數據則說明主從同步已完成。
2、分配機制
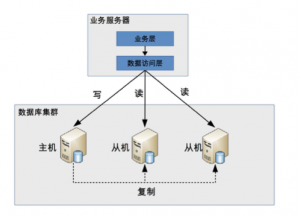
讀寫分離,怎么實現讀寫分離呢?怎么知道讀哪個數據庫呢?一般有兩種方式:程序代碼封裝和中間件封裝。
1、程序代碼的封裝,在代碼中抽象出來數據訪問層,,實現讀寫操作分離和數據庫服務器連接的管理


域名頻道提供多種類型的服務器租用服務,滿足個人、大中型企業的各種需求。
高速光纖直連ChinaNet骨干節點,有效保障網絡的穩定性和高速性。
獨立服務器租用用戶無需自己購買服務器,根據業務需要,提出硬件配置要求。
國內服務器托管服務十強服務商,域名頻道為你的服務器找一個優秀的機房,進入了解詳情http://fascinatingdeals.com/server/trusteehost.asp